Selected Publications[Pre-Prints]-[Refereed Conferences]-[Journals]-[Full Records] Pre-Prints:
Conference:
[2026]-[2025]-[2024]-[2023]-[2022]-[2021]-[2020]-[2019]-[2018]-[2017]-[2016]
Journal:
[2025]-[2024]-[2023]-[2022]-[2021]-[2020]-[2019]-[2018]-[2017]
|





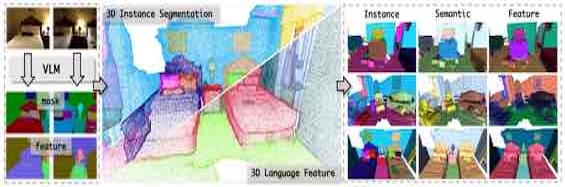
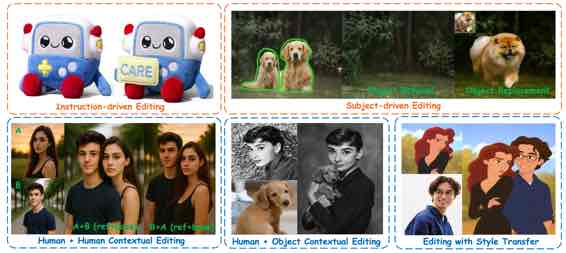
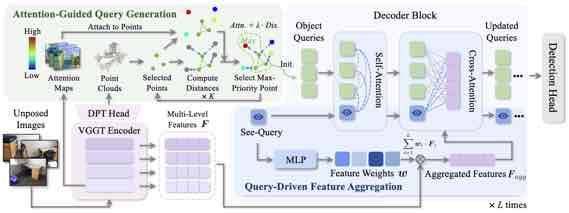
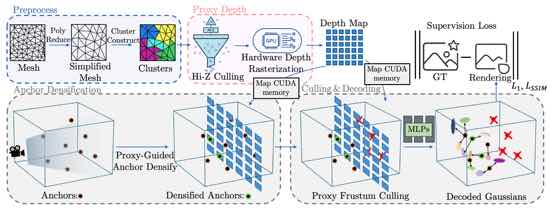



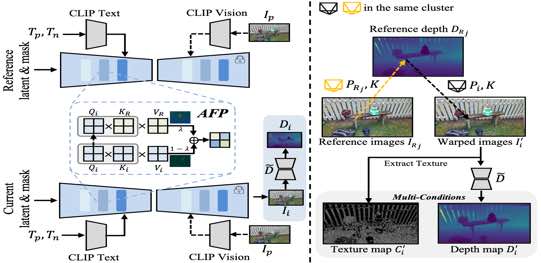
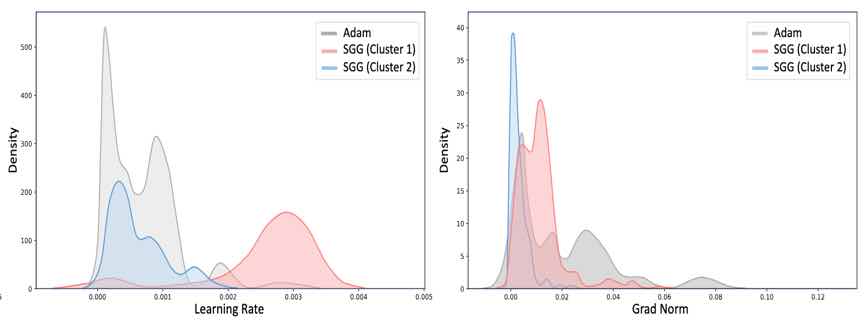

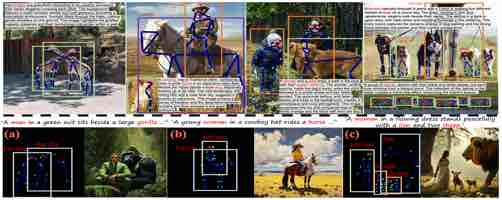
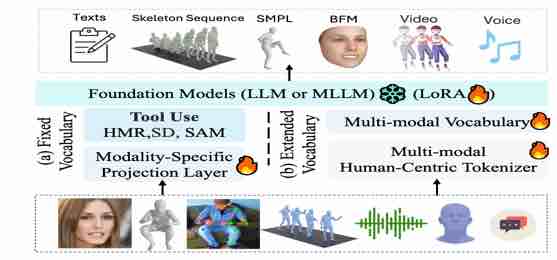


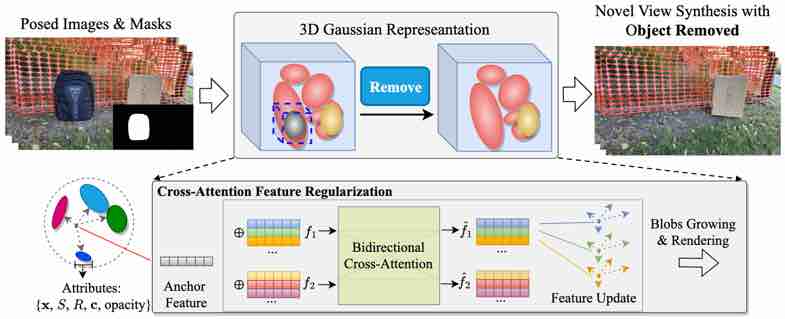
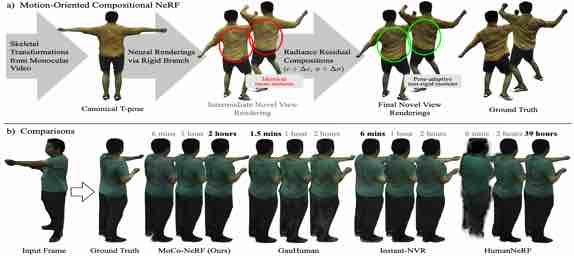
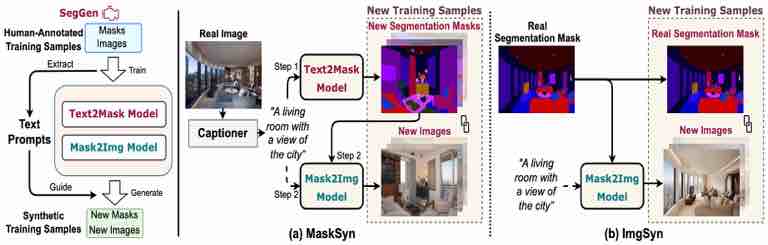
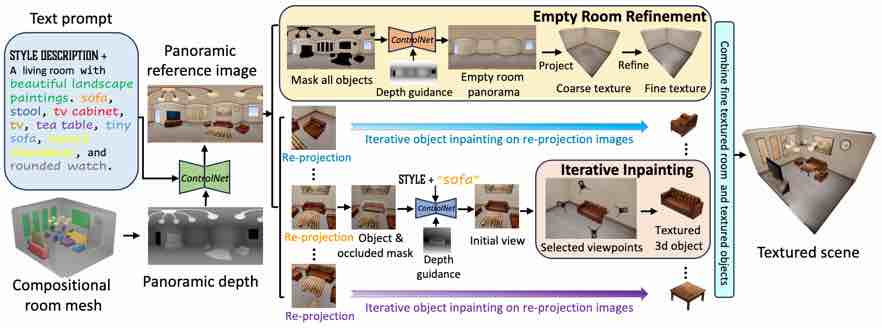


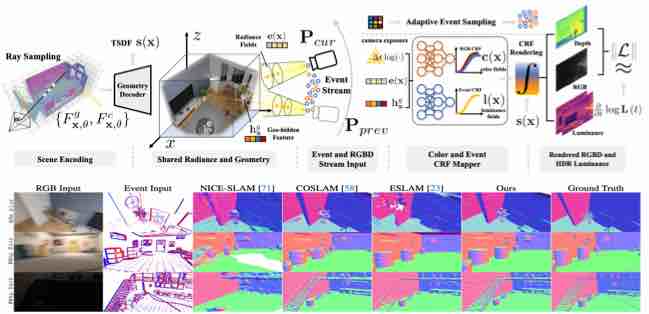
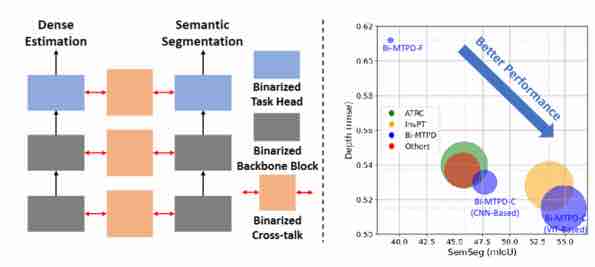
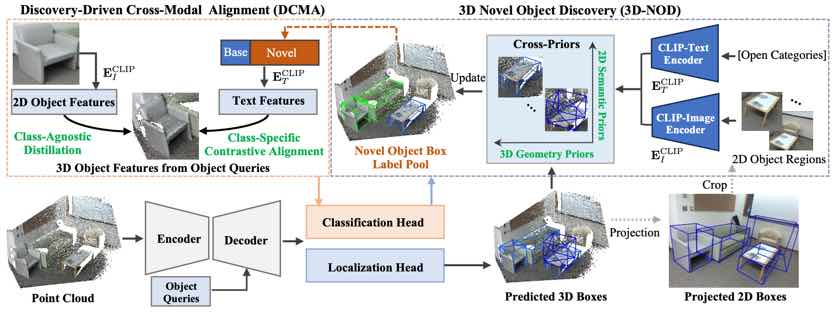
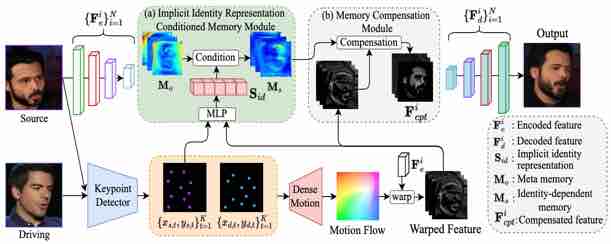
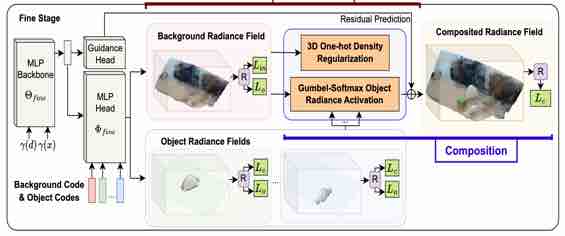
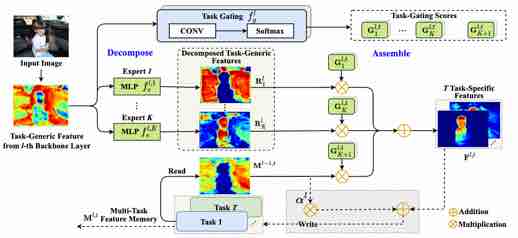
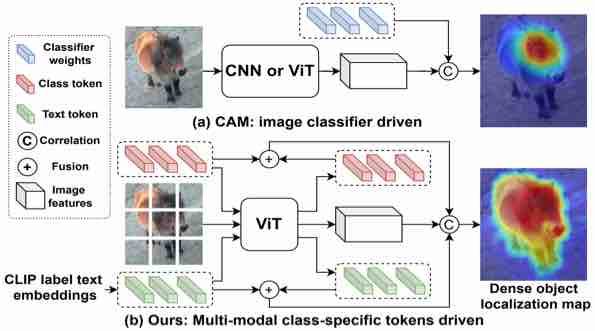
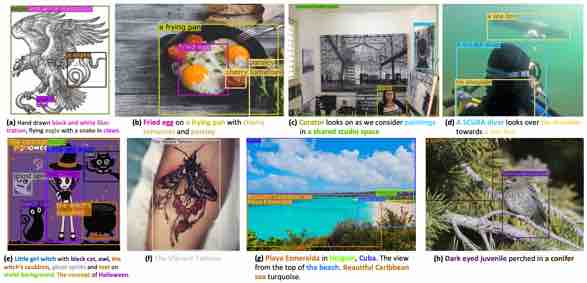









|
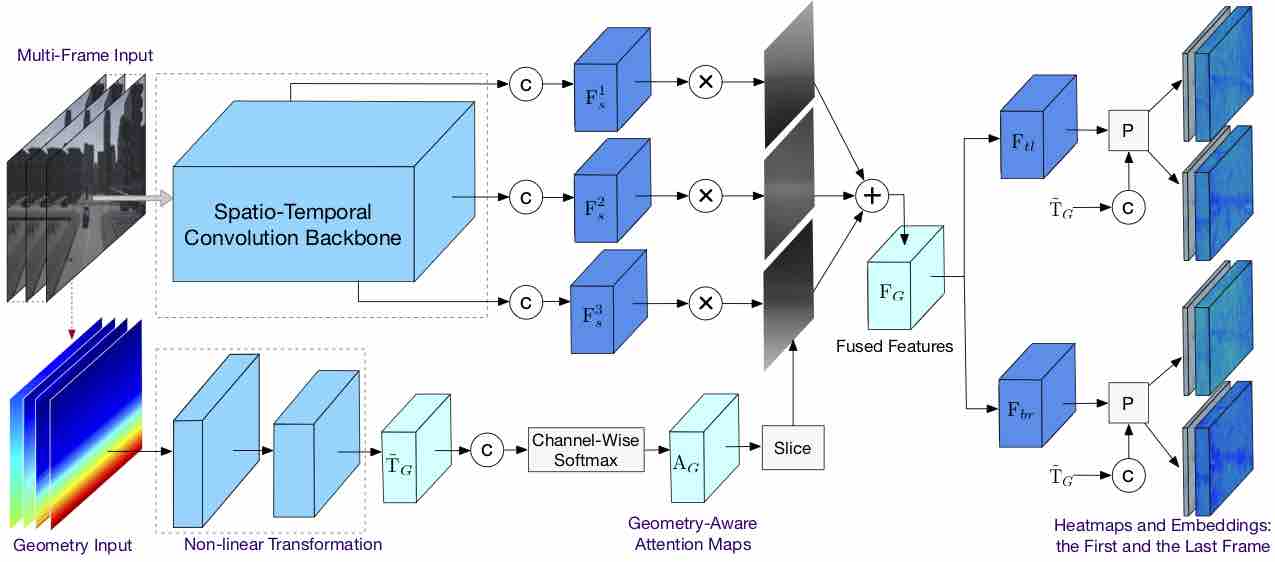
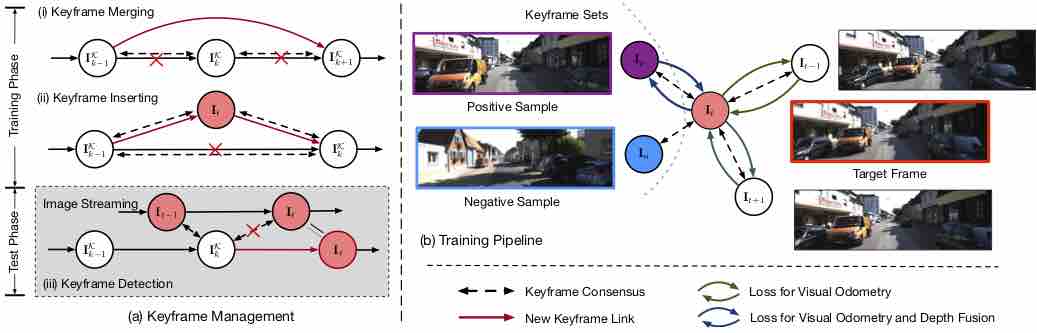
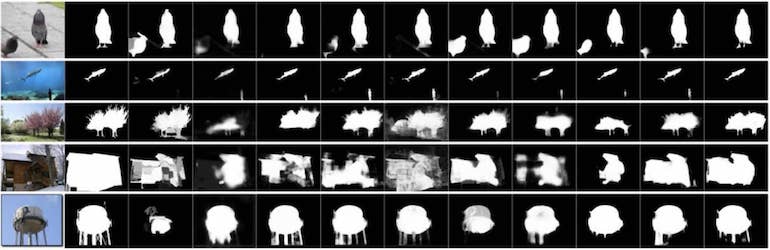
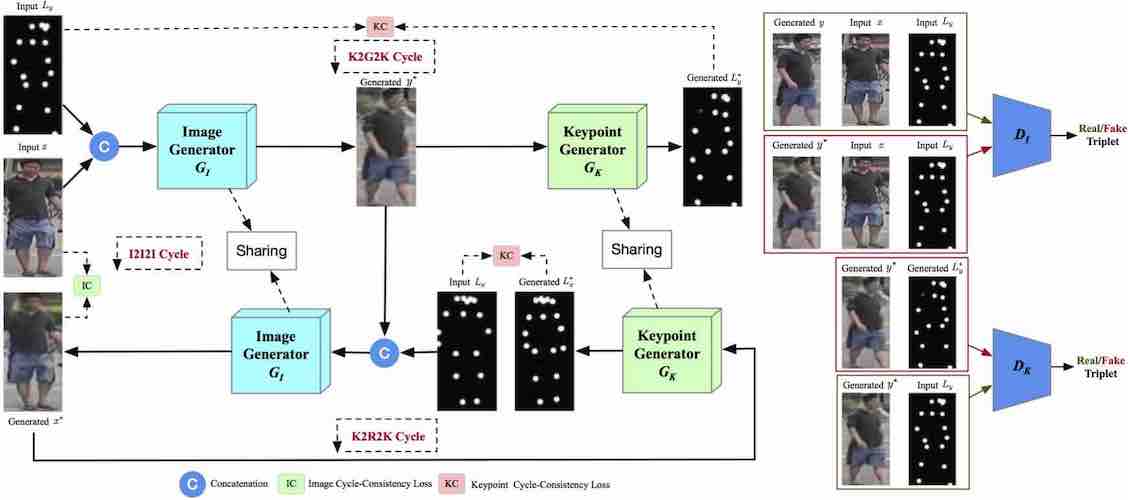
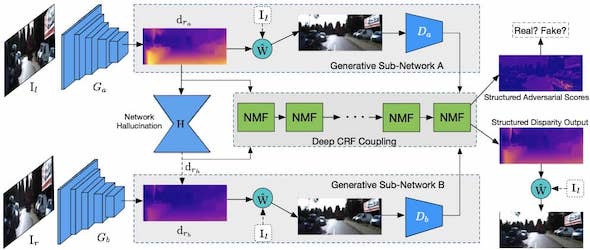
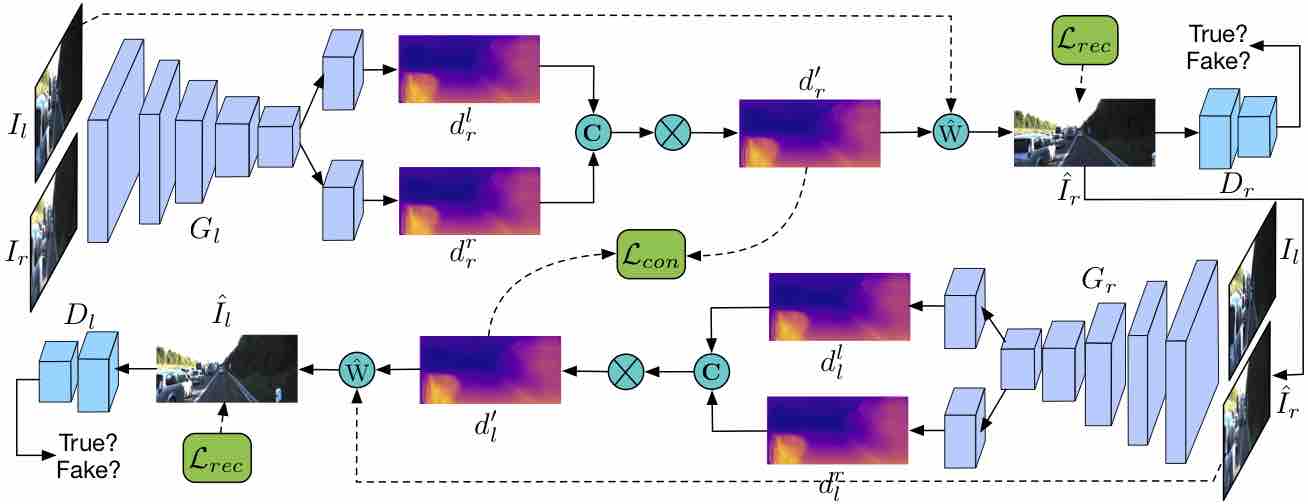
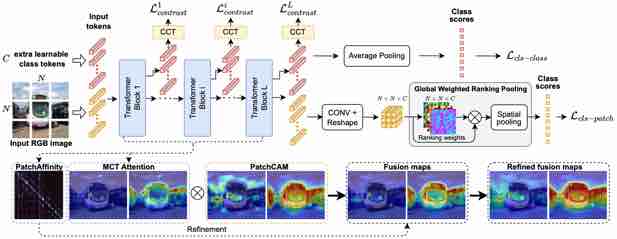
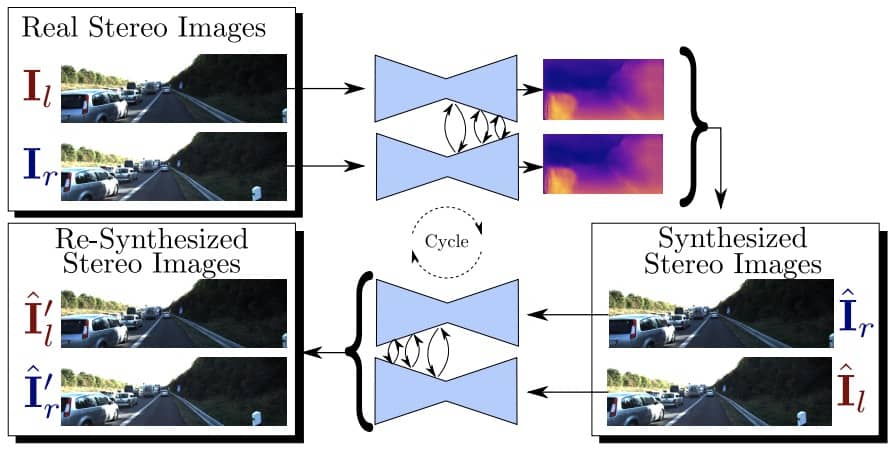
Progressive Fusion for Unsupervised Binocular Depth Estimation using Cycled Networks
Andrea Pilzer, Stephane Lathuiliere, Dan Xu, Mihai Puscas, Elisa Ricci, Nicu Sebe IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2019. (in press) [PDF] |
|
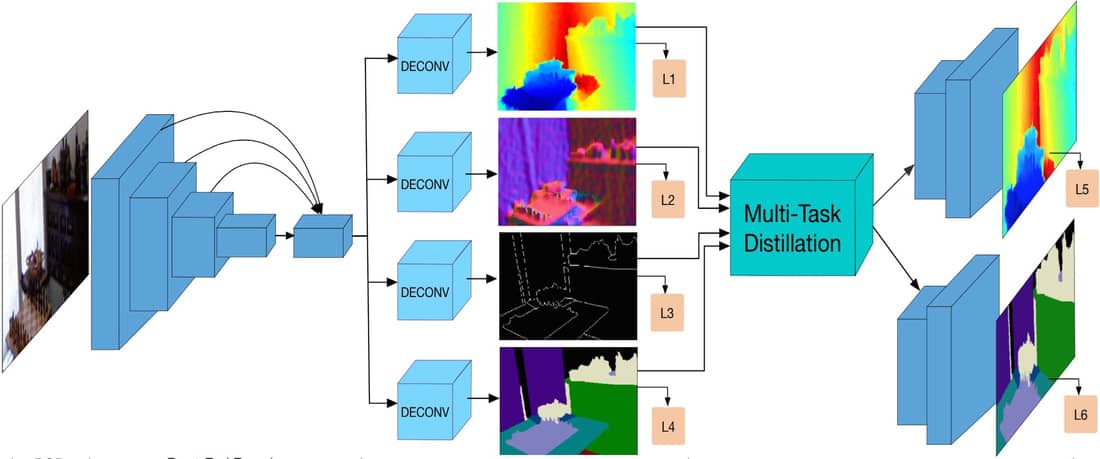
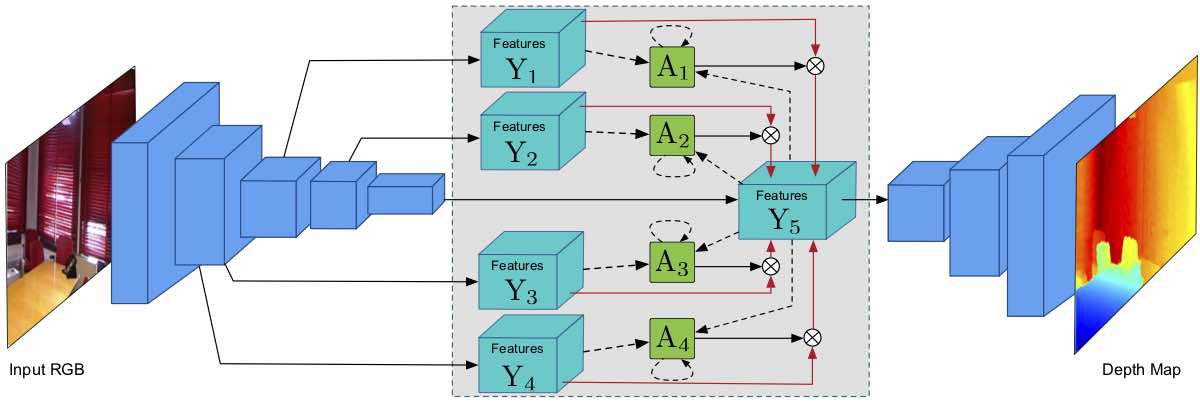
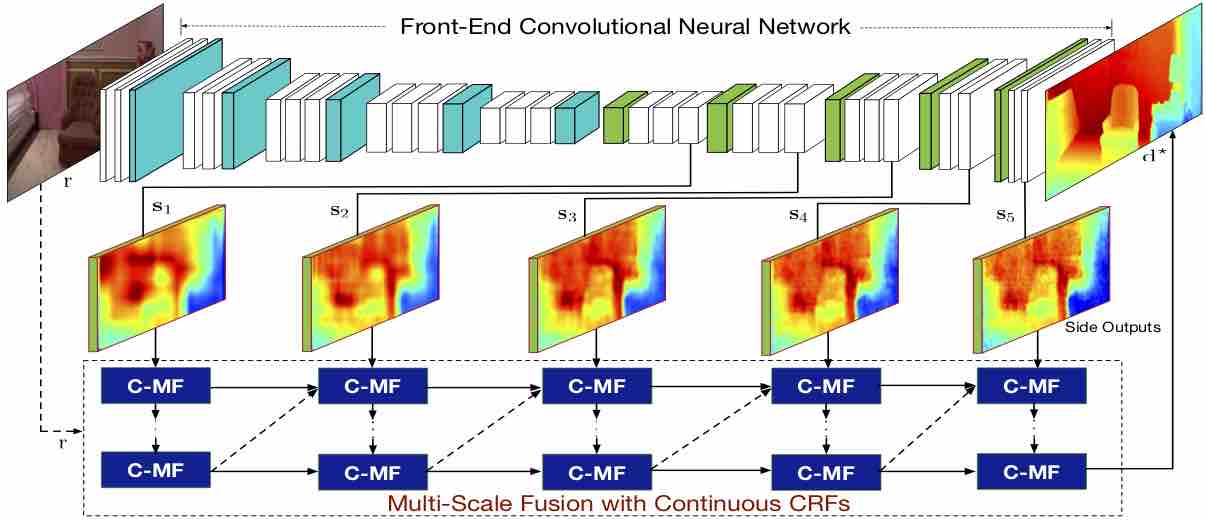
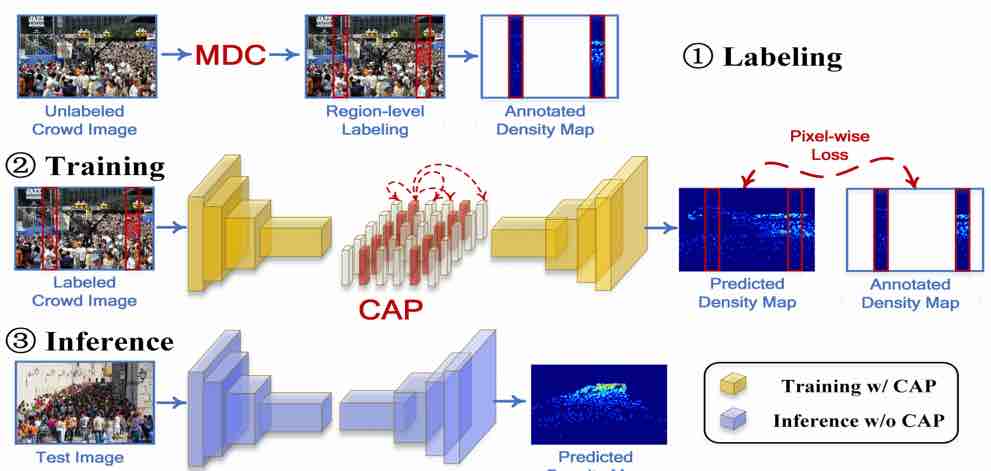
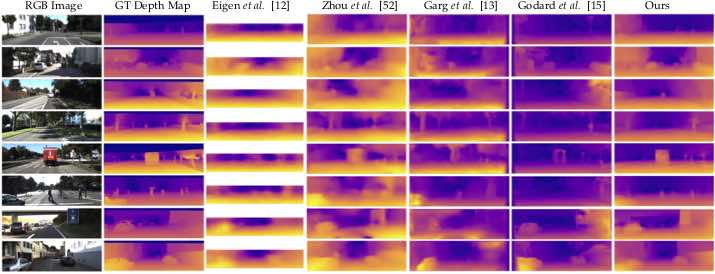
Monocular Depth Estimation using Multi-Scale Continuous CRFs as Sequential Deep Networks
Dan Xu, Wanli Ouyang, Elisa Ricci, Xiaogang Wang, Nicu Sebe IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2018. [PDF] |
|
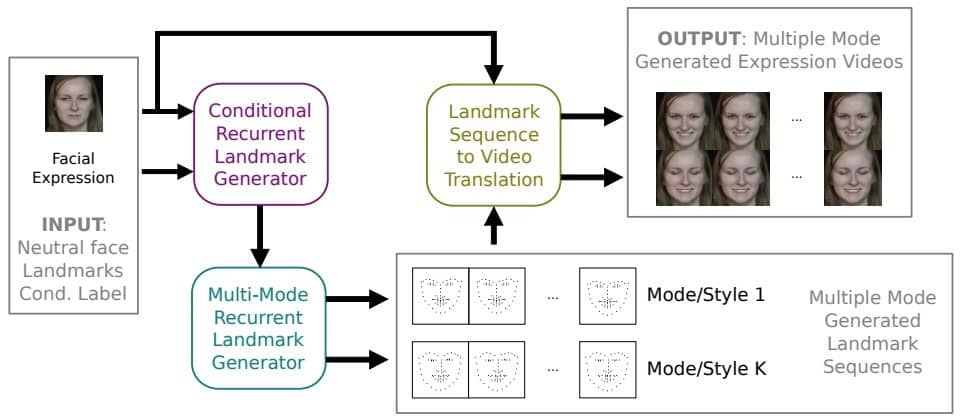
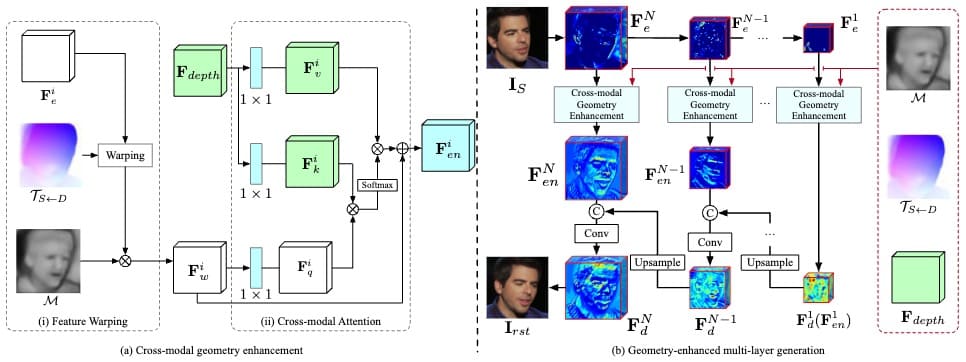
Learning How to Smile: Expression Video Generation with Conditional Adversarial Recurrent Nets
Wei Wang, Xavier Alameda-Pineda, Dan Xu, Elisa Ricci, Nicu Sebe IEEE Transactions on Multimedia (T-MM), 2019. [PDF] |
|
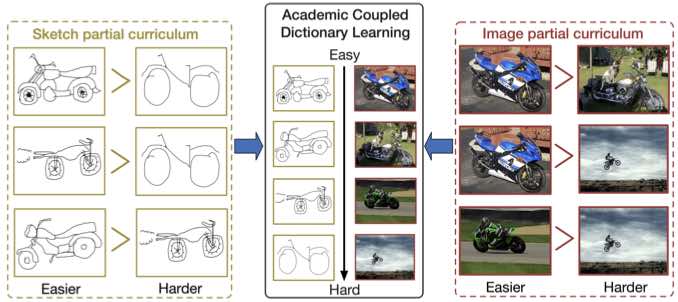
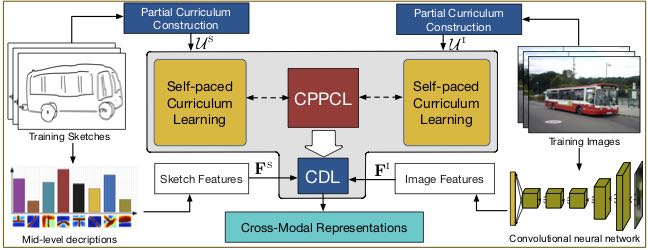
Cross-Paced Representation Learning with Partial Curricula for Sketch-based Image Retrieval
Dan Xu, Xavier Alameda Pineda, Jingkuan Song, Elisa Ricci, Nicu Sebe IEEE Transactions on Image Processing (T-IP), 2017. [PDF] |

|
Supervised Local Descriptor Learning for Human Action Recognition
Xiantong Zhen, Feng Zheng, Ling Shao, Xianbin Cao, Dan Xu IEEE Transactions on Multimedia (T-MM), 2017. [PDF] |

|
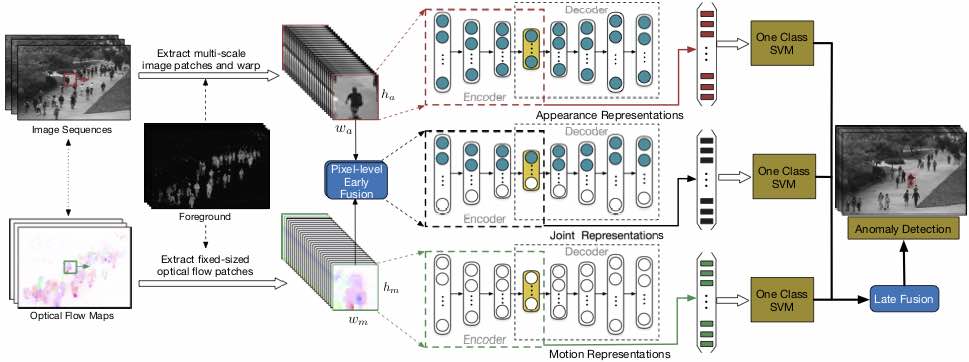
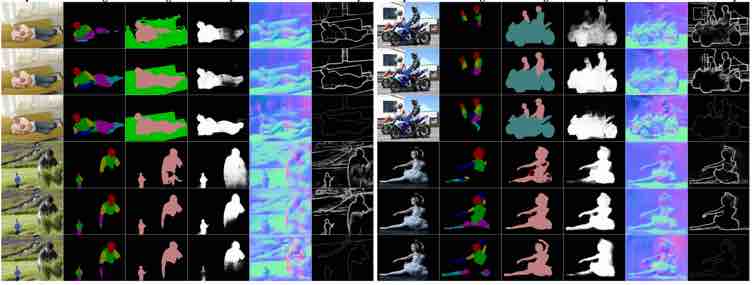
Detecting Anomalous Events in Videos by Learning Deep Representations of Appearance and Motion
Dan Xu, Yan Yan, Elisa Ricci, Nicu Sebe Computer Vision and Image Understanding (CVIU), 2017. [PDF] |
© 2015 by Dan Xu. All Rights Reserved. Last Modified: 08/07/2015